
为什么Kimi-VL值得关注?
最近,我一直在研究多模态AI模型,尤其是那些能同时处理图像和文本的模型。说实话,这个领域的发展速度简直让人眼花缭乱。一边是GPT-4o、Claude 3这样的闭源巨兽,一边是各种开源模型如雨后春笋般涌现。
在这个背景下,Moonshot AI最近发布的Kimi-VL模型引起了我的注意。这个模型有什么特别之处?简单来说:它用2.8B的激活参数,干出了接近或超越那些动辄几十B甚至上百B参数模型的事情。
这就像是一个体重只有60公斤的拳击手,却能在重量级比赛中击败那些体重超过100公斤的对手。这种"以小博大"的技术突破,正是我们在AI民主化道路上迫切需要的。
在这篇文章中,我不会堆砌无意义的技术术语,而是要带你真正理解Kimi-VL的核心创新:它如何通过混合专家架构实现参数效率的飞跃,它的原生分辨率视觉编码器为什么能更好地"看懂"图像,以及它如何通过特殊的训练方法获得"思考"能力。
解密Kimi-VL的核心技术
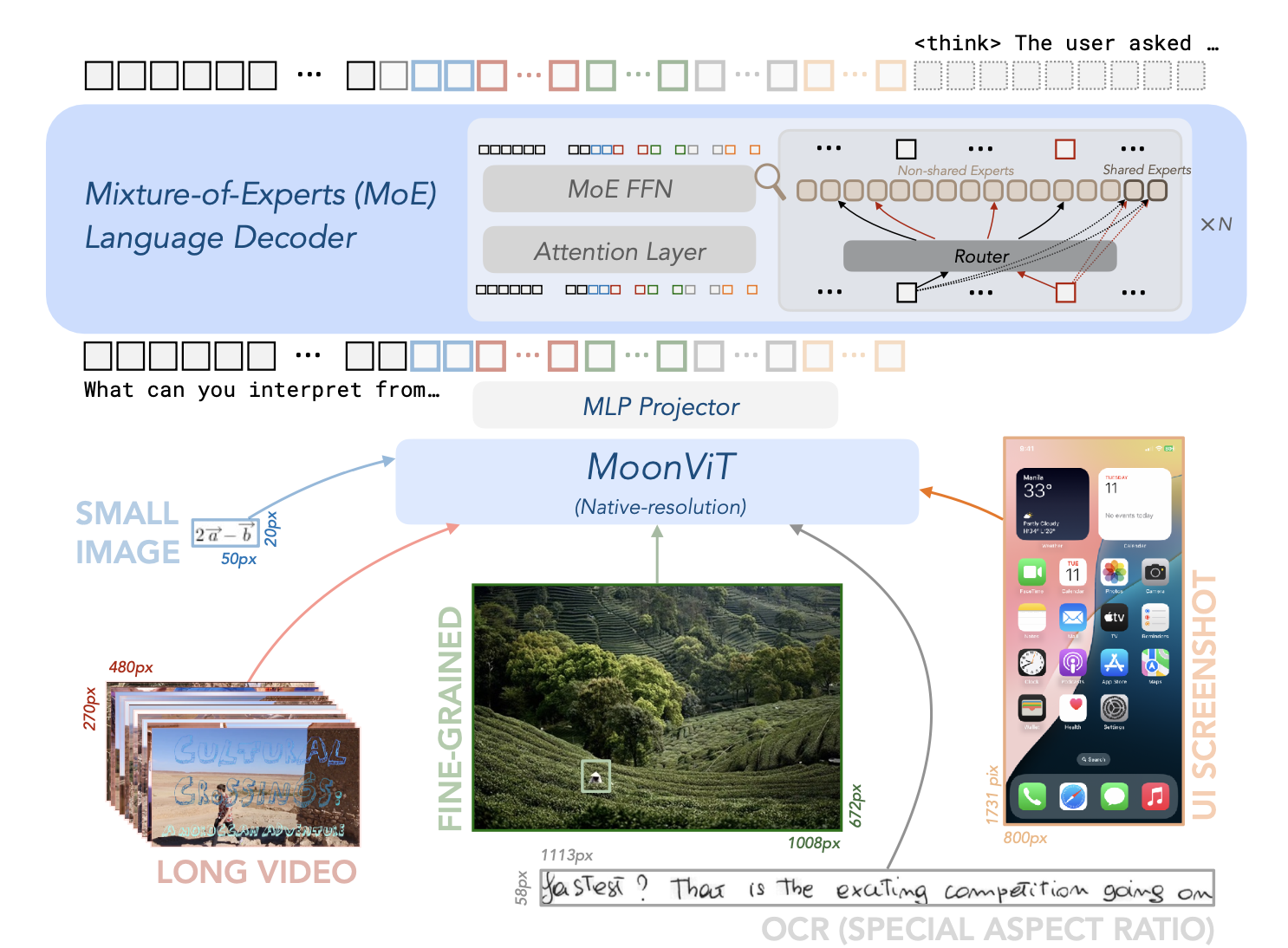
Kimi-VL架构:混合专家语言模型、原生分辨率视觉编码器和MLP投影器
Kimi-VL的架构看起来可能很复杂,但其实可以简单理解为三个关键部分:一个"眼睛"(视觉编码器),一个"翻译官"(MLP投影器),和一个"大脑"(语言模型)。让我们逐一拆解:
1. MoonViT:更聪明的"眼睛"
传统的视觉语言模型在处理图像时,通常会将图像切成固定大小的小块(比如224×224像素),这就像是把一张照片强行裁剪成固定尺寸的小方块。这种方法有个明显的问题:如果图像中有重要信息跨越了这些裁剪边界,模型就可能看不懂。
而Kimi-VL的MoonViT则采用了一种更聪明的方法:它能以原生分辨率处理图像,不管图像是大是小,是宽是窄,都能保持原始比例进行处理。这就像是人类视觉系统,不需要把看到的东西强行切成小块再理解。
具体来说,MoonViT先将图像分割成小块(patches),然后将这些小块展平成一维序列,保持它们的空间关系。这样做的好处是显而易见的:处理高分辨率截图、识别文档中的文字、理解复杂图表,MoonViT都能表现出色,因为它看到的是完整的、未经扭曲的图像。
2. MLP投影器:精准的"翻译官"
视觉和语言是两种完全不同的信息形式,就像中文和英文一样,需要一个"翻译官"来连接它们。在Kimi-VL中,这个角色由MLP投影器担任。
这个投影器并不是简单地将视觉特征直接输入语言模型,而是先进行了一系列精细的处理:首先通过像素混洗操作压缩空间维度(想象成把一张高清照片压缩成略低分辨率但保留关键信息的版本),然后通过两层MLP网络将视觉特征转换成语言模型能理解的表示形式。
这个过程看似简单,但设计精妙。它确保了视觉信息能够无损地转换为语言模型可处理的形式,同时保留了图像中的空间关系和语义信息。
3. 混合专家(MoE)语言模型:高效的"大脑"
这是Kimi-VL最核心的创新点。传统的语言模型是"密集型"的,所有参数都参与每次计算。而Kimi-VL采用的MoE架构则完全不同,它就像是一个由多位专家组成的委员会。
想象一下,如果你有一个问题,你可以选择:1)咨询一个什么都懂一点的通才;2)从一群各有专长的专家中,挑选最适合回答你这个特定问题的几位。显然,后者更有效率。
MoE正是这样工作的:它有一个"门控网络",负责为每个输入决定应该激活哪些"专家"(神经网络子模块)。对于任何给定的输入,只有一小部分专家会被激活,而其余的则保持休眠状态。
这就是为什么Kimi-VL虽然总参数量达到16B,但每次推理只需激活2.8B参数。这种设计带来了两个巨大优势:一是计算效率高,推理速度快;二是模型容量大,能够学习和存储更多知识。
简单来说,MoE架构让Kimi-VL能够以小模型的速度,发挥大模型的能力。这就像是一个轻量级拳手,却拥有重量级的力量。
Kimi-VL的两种形态:通用型vs思考型
Kimi-VL提供了两个主要变体,就像是同一个AI的两种不同性格:一个更擅长快速理解和回应(Instruct版本),另一个则更善于深度思考和推理(Thinking版本)。
- Kimi-VL-A3B-Instruct:这是日常使用的通用版本,适合大多数场景,如图像描述、OCR识别、视频理解、多轮对话等。它反应快速,理解准确,是一个全能型选手。
- Kimi-VL-Thinking:这是经过特殊训练的"思考型"版本,特别擅长需要深度推理的任务,如数学问题、逻辑推理、复杂分析等。它会生成详细的思考过程,让你看到它是如何一步步得出结论的。
两个版本的参数量相同,都是总共16B参数,激活3B参数,上下文窗口都达到了惊人的128K(相当于约10万个英文单词)。这意味着它们可以处理非常长的文本和多张图像,甚至是视频序列。
| 模型 | 总参数量 | 激活参数量 | 上下文长度 | 下载链接 |
|---|---|---|---|---|
| Kimi-VL-A3B-Instruct | 16B | 3B | 128K | 🤗 Hugging Face |
| Kimi-VL-A3B-Thinking | 16B | 3B | 128K | 🤗 Hugging Face |
"以小博大":Kimi-VL如何击败大模型?
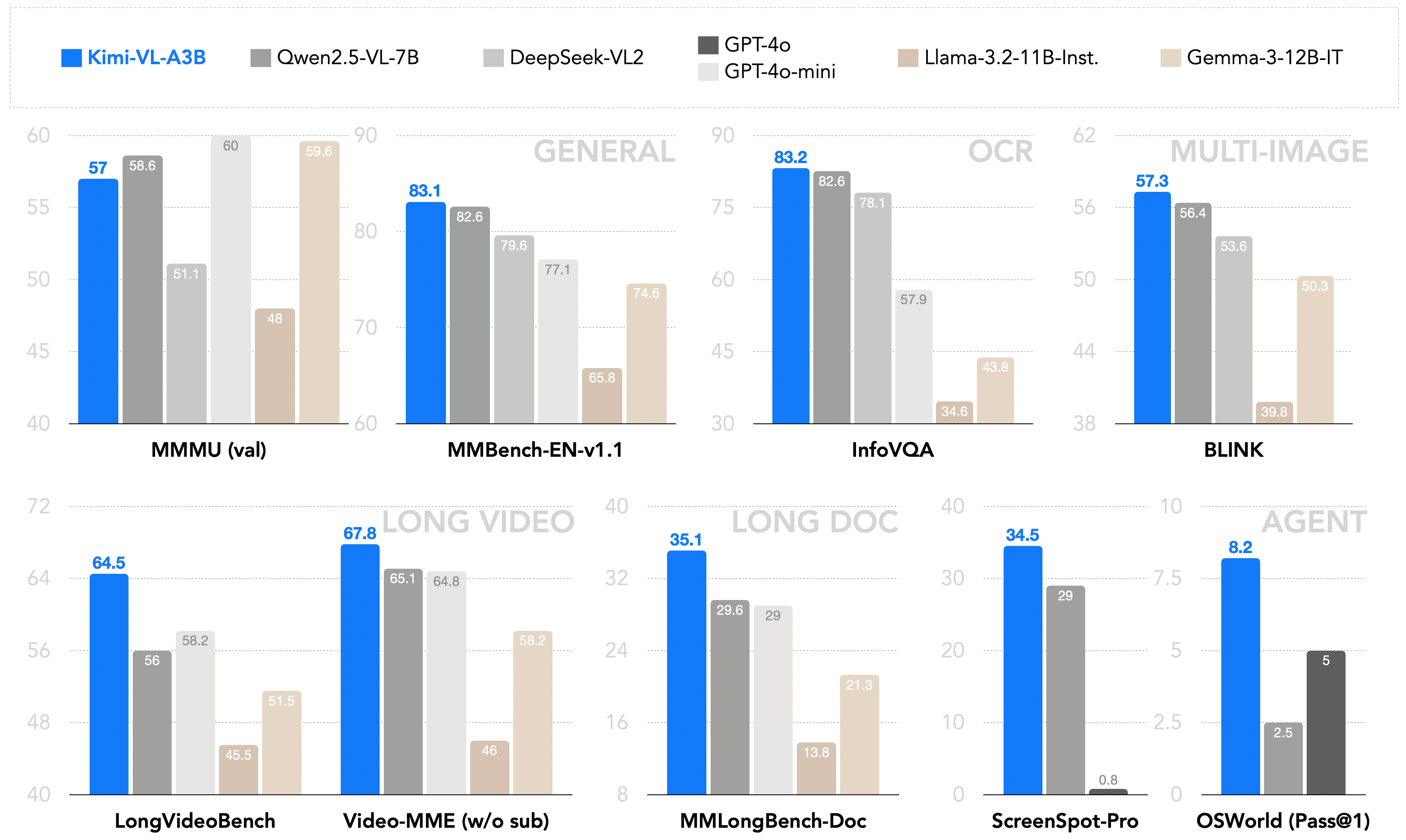
Kimi-VL与现有10B级别密集VLM和DeepSeek-VL2(A4.5B)的性能对比
数据会说话,而Kimi-VL的性能数据简直是在大声喊话:小模型也能有大能力!让我们看看它在几个关键领域的表现,以及背后的技术原因:
文档理解与OCR:超越GPT-4o
在InfoVQA测试中,Kimi-VL得分83.2%,超过了GPT-4o(80.7%)。在OCRBench测试中,它得分86.7%,远超GPT-4o-mini(78.5%)。
为什么能做到?这要归功于MoonViT的原生分辨率处理能力。传统模型在处理文档时,往往需要将图像切割成小块,导致文字可能被分割,上下文关系丢失。而Kimi-VL能够保持文档的完整性,就像人类阅读文档一样,自然地从上到下、从左到右理解内容。
数学推理:小模型解大题
在MathVista测试中,Kimi-VL得分68.7%,超过了GPT-4o(63.8%)。而Thinking版本更是达到了71.3%的惊人成绩。
为什么能做到?这里的秘密在于MoE架构和特殊的训练方法。MoE允许模型在不同类型的问题上激活不同的"专家",对于数学问题,它可能会激活更擅长逻辑和符号推理的专家子网络。而Thinking版本则通过长链思考(CoT)训练,学会了像人类一样一步步推导问题。
长文档和视频理解:超长上下文的威力
在MMLongBench-Doc测试中,Kimi-VL得分35.1%,远超GPT-4o-mini(29.0%)。在长视频理解方面,它在LongVideoBench上得分64.5%,同样领先其他同级模型。
为什么能做到?这得益于Kimi-VL的128K超长上下文窗口和特殊的长上下文训练。大多数模型的上下文窗口只有几千到几万个token,而Kimi-VL的128K窗口允许它同时处理大量文本和多张图像,甚至是视频序列。这就像是拥有超强工作记忆的人,能够在处理新信息的同时,记住之前看到的所有内容。
代理交互:超越GPT-4o的智能助手
在OSWorld测试中,Kimi-VL得分8.22%,超过了GPT-4o(5.03%)。这是一个测试模型在操作系统环境中执行复杂任务能力的基准。
为什么能做到?这里的关键是Kimi-VL对视觉信息的精确理解和对长上下文的把握。在操作系统环境中,模型需要理解屏幕上的各种元素(按钮、菜单、文本框等),记住之前的操作步骤,并规划下一步行动。Kimi-VL的原生分辨率视觉处理和长上下文能力,使它能够像人类一样"看懂"屏幕,并在多轮交互中保持连贯性。
思考的艺术:Kimi-VL如何学会推理?
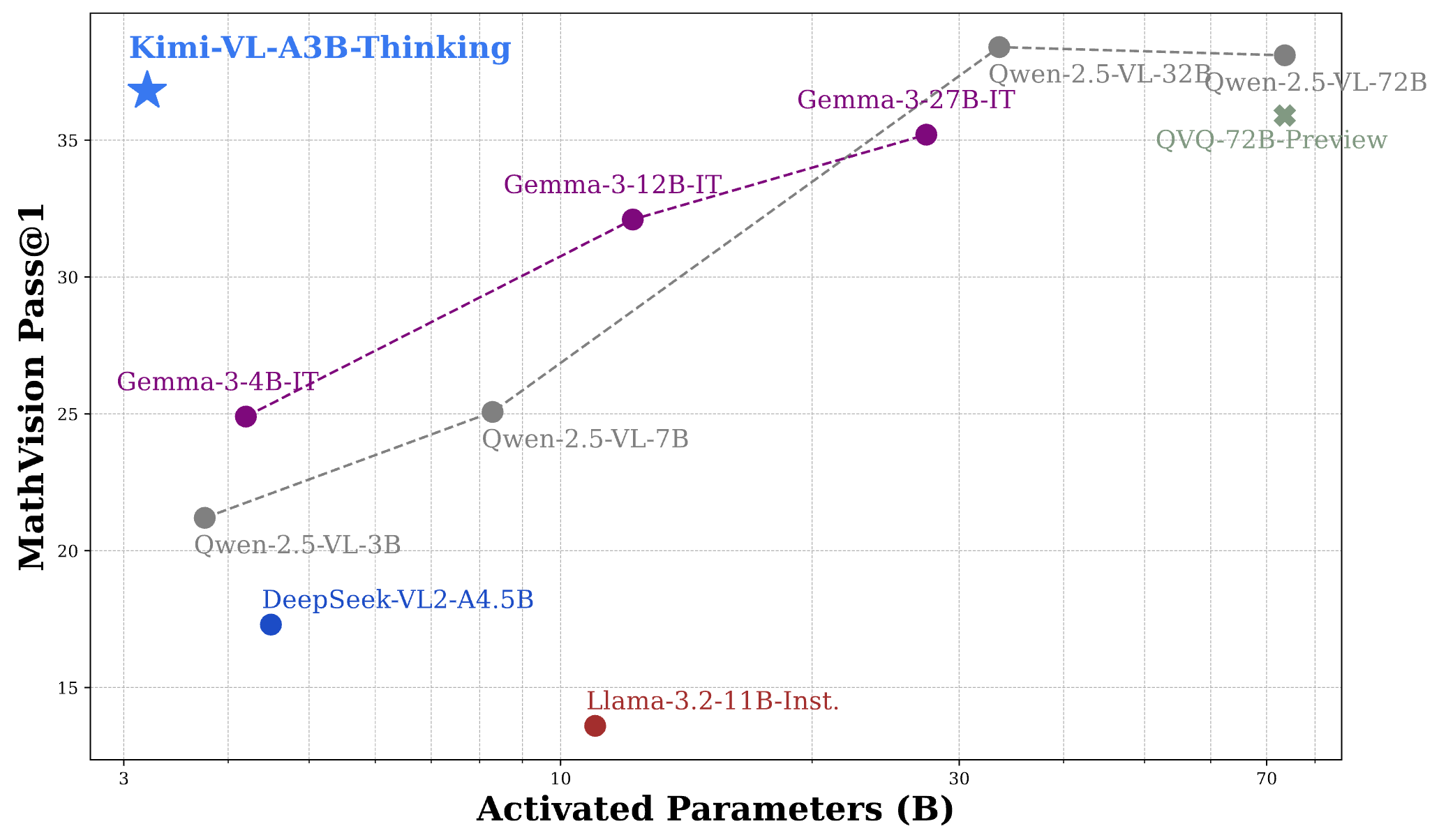
Kimi-VL-Thinking在MathVision基准测试上与30B/70B前沿开源VLM的性能对比
AI的"思考"能力一直是个难题。大多数模型只会给出答案,却不会解释推理过程。而Kimi-VL-Thinking则不同,它不仅能给出答案,还能展示详细的思考过程。这种能力是如何实现的?
从"知道"到"理解"的飞跃
Kimi-VL-Thinking是在基础Kimi-VL模型上,通过两个关键步骤打造的:
- 长链思考(CoT)监督微调:研究人员收集了大量包含详细推理过程的问题-答案对,用这些数据训练模型,教会它如何一步步思考问题。这就像是教一个学生不仅要给出答案,还要写出完整的解题过程。
- 强化学习(RL):在监督微调的基础上,研究人员使用强化学习技术,让模型学会自主生成结构化的思考理由。这相当于让学生自己练习解题,并根据答案的正确与否给予反馈,使其逐渐掌握推理的技巧。
思考的长度与质量
Kimi-VL-Thinking展示了一个有趣的现象:思考的越多,答案越准确。从图表中可以看到,随着允许模型思考的token数量从1k增加到16k,准确率稳步提升:
- 在MathVision上,准确率从18.7%提升到36.8%,几乎翻了一倍
- 在MMMU上,准确率从49.2%提升到61.7%,提高了12.5个百分点
- 在MathVista上,准确率从66.7%提升到71.3%,提高了4.6个百分点
这种现象与人类思考非常相似:给我们更多时间思考复杂问题,通常能得出更准确的答案。Kimi-VL-Thinking模拟了这种深度思考的过程,不是简单地"猜"答案,而是通过系统性的推理得出结论。
透明的思考过程
Kimi-VL-Thinking最大的价值在于它的思考过程是完全透明的。当它解决一个数学问题时,你可以看到它如何分解问题、应用公式、进行计算,最后得出答案。这种透明性有两个重要意义:
- 可解释性:用户可以理解模型为什么给出特定答案,增强对AI的信任
- 教育价值:模型的思考过程可以作为学习材料,帮助人类理解复杂问题的解决方法
这种能力使Kimi-VL-Thinking不仅是一个回答问题的工具,更是一个能够展示思考艺术的AI助手。
实战应用:如何驾驭Kimi-VL的能力?
理论讲完了,来点实际的。Kimi-VL作为一个开源模型,任何人都可以下载使用。这里我给出几个实际应用场景和相应的代码示例,让你快速上手这个强大的工具。
基础图像理解:让AI描述你的照片
最简单的应用是让Kimi-VL描述图像内容。这个功能可以用于自动生成图片描述、辅助视障人士理解图像、自动标记图片等场景。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from PIL import Image
# 加载模型和分词器
model_name = "moonshotai/Kimi-VL-A3B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# 准备图像和提示
image = Image.open("example.jpg")
prompt = "请描述这张图片中的内容"
# 构建输入
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": image}}
]}
]
# 生成响应
input_ids = tokenizer.apply_chat_template(
messages,
return_tensors="pt"
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.9,
)
response = tokenizer.decode(outputs[0][input_ids.shape[1]:], skip_special_tokens=True)
print(response)文档理解与OCR:智能文档助手
Kimi-VL在文档理解和OCR方面表现出色,可以用于构建智能文档助手,帮助用户提取、总结和分析文档内容。
# 使用相同的模型加载代码
# 准备文档图像和提示
document_image = Image.open("document.jpg")
prompt = "请提取这份文档中的关键信息,包括标题、日期、主要内容和结论"
# 构建输入
messages = [
{"role": "system", "content": "你是一个专业的文档分析助手,擅长从文档中提取关键信息。"},
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": document_image}}
]}
]
# 生成响应
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
outputs = model.generate(input_ids, max_new_tokens=1024, do_sample=True, temperature=0.3)
response = tokenizer.decode(outputs[0][input_ids.shape[1]:], skip_special_tokens=True)
print(response)数学问题求解:使用Thinking版本
对于复杂的数学问题,特别是需要多步推理的问题,Thinking版本能够提供详细的解题过程,非常适合教育场景。
# 加载Thinking版本模型
model_name = "moonshotai/Kimi-VL-A3B-Thinking"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# 准备数学问题图像和提示
math_image = Image.open("math_problem.jpg")
prompt = "请解决这个数学问题,并展示详细的解题步骤"
# 构建输入
messages = [
{"role": "system", "content": "你是一个数学教师,擅长解决复杂的数学问题并提供清晰的解题思路。"},
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": math_image}}
]}
]
# 生成响应,允许更长的思考过程
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=2048, # 允许更长的输出
do_sample=True,
temperature=0.2, # 降低温度以获得更确定性的答案
)
response = tokenizer.decode(outputs[0][input_ids.shape[1]:], skip_special_tokens=True)
print(response)实际应用场景
除了上述基础示例,Kimi-VL还可以应用于多种实际场景:
- 智能教育助手:解答学生拍照上传的作业问题,提供详细解释和思路指导
- 文档自动化处理:自动提取合同、发票、报告等文档中的关键信息,减少人工处理时间
- 视觉辅助系统:帮助视障人士理解周围环境,描述图像和文本内容
- 多模态内容分析:分析社交媒体、新闻、广告等包含图像和文本的内容,提取洞见
- 智能客服:理解用户上传的产品图片或截图,提供相应的技术支持和解决方案
Kimi-VL:开源多模态的新标杆
回顾Kimi-VL的核心创新,我不禁感叹:这是开源多模态模型的一个重要里程碑。它通过混合专家架构、原生分辨率视觉处理和长上下文理解,实现了"以小博大"的技术突破。
对我而言,Kimi-VL最令人兴奋的不仅是它的技术创新,更是它所代表的AI民主化方向。当一个只有2.8B激活参数的模型能够在多个领域超越或接近那些参数量是它10倍甚至100倍的专有模型时,这意味着高质量的AI能力正在变得更加普及和平民化。
当然,Kimi-VL也有其局限性。它在某些高度专业化的领域知识上仍有不足,对于极其复杂的多步推理任务也有提升空间。但考虑到它的参数效率和开源性质,这些局限完全可以理解,并且有望在未来版本中得到改进。
作为一个长期关注AI发展的观察者,我认为Kimi-VL代表了一个重要趋势:AI的未来不仅仅属于那些拥有海量计算资源的科技巨头,也属于那些能够通过创新架构和算法实现效率突破的团队。这种趋势将加速AI的普及和应用,让更多人能够受益于这一技术革命。
如果你是开发者、研究者或者对多模态AI感兴趣的爱好者,我强烈建议你尝试Kimi-VL。它不仅是一个强大的工具,更是一个学习和探索多模态AI前沿的绝佳窗口。